Erreurs et regrets
"Oopsie doopsie" et autres "ça marche pas"
La gestion des erreurs a toujours été un truc qui me met mal à l'aise dans le cadre de mon travail, ou de la création de petits projets personnels.
Inévitables, les erreurs doivent répondre à quelques contraintes qui sont pourtant assez souvent négligées:
- Information de l'utilisateur: quelque chose s'est "mal passé", il doit le savoir, et être en mesure d'apporter une réponse plus ou moins satisfaisante à la problématique.
- Information du développeur: une erreur classique (et aux conséquences désastreuses) en programmation informatique consiste à intercepter une erreur et de ne rien en faire. Dans tous les cas, une erreur inattendue par le système se doit d'être remontée au développeur (et donc à minima stockée quelque part).
- Protection du système: les erreurs doivent être gérées de telle manière qu'elles n'exposent pas d'informations sensibles ni à l'utilisateur, ni au développeur (et par extension à n'importe quel type relativement malveillant qui chercherait à abuser du système). Elles ne doivent pas mettre en danger l'état général de l'application ou corrompre les données saisies par l'utilisateur.
Si elles me semblent si complexes à mettre en œuvre, c'est certainement parce qu'elles nécessitent de s'interroger clairement, pour chaque interaction homme-système, sur ce qu'il pourrait mal se passer. Et ça, ça implique de se poser des questions relativement désagréables en tant que développeur, mais aussi et surtout à bien maîtriser sa création en tant que concepteur. Pour chaque sortie de rail, il faut être en mesure d'identifier quelle information présenter à l'utilisateur et surtout, déterminer quelle solution lui proposer pour que le problème ne se présente pas à nouveau.
Le cas le plus simple de tels raisonnements prend certainement forme dans le cadre des réflexions autour de la validation de formulaire: probablement l’occurrence de ces problématiques d'erreur la plus complexe à gérer, c'est aussi celle dont la gestion est le plus souvent correctement mise en œuvre. Il est possible d'imaginer que c'est le cas étant donné que, d'une part, nous avons tous été confrontés à des formulaires merdiques dans notre vie (coucou l'ANTS), et que d'autre part, puisqu'il s'agit de faire entrer des données dans un système informatique, le développeur prendra un soin particulier de s'assurer qu'on enregistre pas n'importe quoi.
.png.webp)
Il est aussi important de noter que les navigateurs modernes et les spécifications DOM rendent l'implémentation d'une telle gestion plutôt aisée (du moins coté front).
Décidant donc de dépasser mon aversion toute personnelle qui me maintenait dans l'illusion que non, tout irait bien malgré la tendance des utilisateurs à repousser toutes les limites des pauvres systèmes sans défense que je ponds, je me suis donc décidé à réfléchir sur la question.
Voici donc quelques stratégies qui m'ont traversé l'esprit:
Fournir du contexte
La simple erreur technique présentée dans toute sa brutalité à l'utilisateur ne lui apporte qu'une aide relative (comprendre: aucune). Pas de différence profonde entre un message Oopsie-doopsisant ou une stacktrace de 300 lignes, si ce n'est que la deuxième option peut-être plus oppressante.
Il s'agit donc, comme bien souvent, de s'expliquer si possible sans apporter de jargon trop technique à l'information, d'ajouter du contexte.
L'idée est donc la suivante: attraper l'erreur effective le plus tôt possible, lui accoler des informations sur son contexte d'un point de vue utilisateur ET technique puis la laisser remontrer librement jusqu'à un point d'attache unique qui lui se chargera de la présenter à l'utilisateur, de la faire remonter au système de collecte des erreurs (eg: logs ou sentry) et d'affecter l'état général de l'application en fonction de l'erreur. Cette dernière possibilité est d'autant plus pertinente qu'ajouter de l'information contextuelle à l'erreur permet de préciser si l'application peut se remettre d'elle-même dans le droit chemin sans profondément modifier son état ou s'il vaut mieux faire table rase du passé.
Bonus point si la présentation de l'erreur simplifie la communication entre le support et l'utilisateur lorsque vient le besoin de causer.
Supprimer les erreurs
Jeff Raskin, chef de projet Macinthosh chez Apple fin 70 et maître à penser radical de son état, recommande de purement et simplement renoncer au concept d'erreur d'un point de vue expérience utilisateur.
Deux stratégies possibles selon le grand homme:
- Intégrer l'erreur au fonctionnement du logiciel: dans un logiciel de calcul, plutôt que de planter le système à la division par 0, créer une nouvelle valeur NaN (Pas Un Nombre dans la langue de Renaud) qui sera renvoyée à toute opération invalide. Toute nouvelle opération réalisée sur NaN renverra elle aussi NaN. L'utilisateur est ainsi en mesure de se rendre compte du problème sans pour autant arriver à un état d'erreur proprement dit.
- Limiter le problème à un niveau purement informatif sans jamais interrompre la manipulation de l'utilisateur. Comprendre: supprimer l'état d'erreur. Le système doit alors être en mesure d'identifier des stratégies de rétablissement de son état.
À noter que ces stratégies ne s'appliquent réellement qu'auprès des erreurs sur lesquelles l'utilisateur peut agir (actionnables). Les erreurs système, comprendre indépendantes de la seule saisie de l'utilisateur, ne devraient pas interférer sur la validité de la saisie ou permettre de continuer la manipulation dans un état potentiellement corrompu (sans stratégie de gestion).
Levier et blocage
Infine et en ce qui concerne l'utilisateur il n'existe fondamentalement pas d'erreur système (eg: réseau, HTTP 50x) ou utilisateur (eg: HTTP 40x). Il existe en revanche des erreurs sur lesquelles il peut agir en autonomie et d'autres où il ne peut le faire.
Si possible en dehors d'erreurs imprévisibles résultant de réels bugs (état non prévu par le code), il s'agit donc d'intégrer tous les cas problématiques au système de manière à ne pas interrompre la manipulation de l'interface, de maximiser le niveau d'autonomie de l'utilisateur.
Pour ce faire il est donc de bon ton:
- D'ajouter un maximum d'informations pertinente pour l'utilisateur sur ce qui se passe.
- De toujours lui proposer des leviers ou des actions pour sortir à terme de l'état problématique.
- Dans le cas d'une erreur sur laquelle un utilisateur ne peut fondamentalement pas agir (indisponibilité d'un serveur par exemple), de lui fournir le moyen de remonter l'information à une personne pouvant, elle, faire quelque chose.

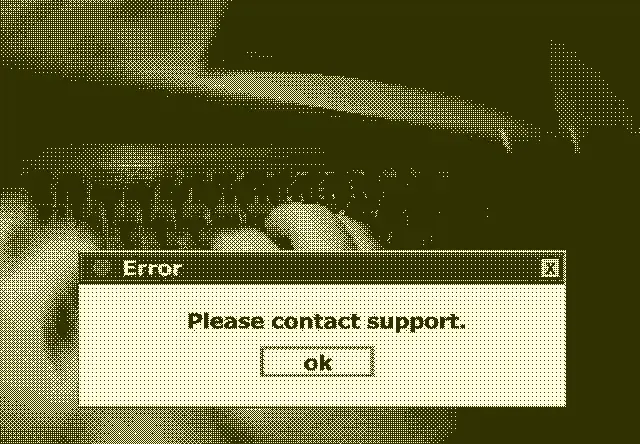
Concernant ce dernier point, l'illustration de ce billet, cas d'école s'il en est, illustre une gestion bien insuffisante: On dit à l'utilisateur de s'adresser au support, sans lui donner d'informations ou lui indiquer quoi dire à son futur interlocuteur. Une telle alert ne pourra amener qu'à un "ça marche po" si apprécié.
Processus
La proposition ci-dessous ne casse pas des barreaux de chaise, et n'a encore jamais été réellement testée dans un contexte de création de produit, néanmoins, c'est toujours chouette d'avoir un cadre auquel se référer donc voici l'idée:
- Identification des erreurs au sens produit: Tout logiciel doit être conçu de manière à ce que la navigation d'un utilisateur en son sein soit la plus sûre possible. Comprendre: ne pas construire les User-Stories ou autres spécifications uniquement sous un angle positiviste comme c'est souvent fait: identifier les cas vides, les situations induites par une navigation en arrière de l'utilisateur, par une typo dans sa saisie etc...
- Identification des erreurs au sens techniques:
- Examiner toutes les erreurs techniques possibles. eg: Pour chaque appel à une API, identifier les codes d'erreurs particuliers pouvant être renvoyés et prévoir une stratégie de gestion en lien avec le fonctionnement de l'application.
- Pour chaque erreur, déterminer si sa résolution est sous le contrôle de l’utilisateur ou non.
- Gestion des erreurs non-actionnable par l’utilisateur:
- Mettre en place une stratégie permettant à l’utilisateur de signaler rapidement l’erreur à quelqu’un ayant le pouvoir de la résoudre.
- Par exemple, proposer un formulaire de rapport de bug ou un moyen de contacter l’administrateur/développeur.
- Traitement des erreurs contrôlables par l’utilisateur: Réfléchir à une stratégie d’information qui signale le problème à l’utilisateur sans interrompre sa manipulation.
Sources
Display state of objects, The Humane interface, Jeff Raskin p. 115
Errors https://buildtogether.tech/errors/
Codepaths ! And some strategies to reduce the codepath numbers https://www.rfleury.com/p/the-easiest-way-to-handle-errors
Details on codepath https://www.rfleury.com/p/a-taxonomy-of-computation-shapes